Improving the lifetime operation of today’s digital healthcare devices
By Andrew Caples, product marketing manager, Embedded Software Division (ESD), Mentor Graphics
Electronics Engineering Medical Supply Chain digital healthcareIntroduction
Digital healthcare devices that enable remote patient care and provide increased mobility in hospital environments are seeing a significant increase in use and popularity. New hardware availability, the emergence of the Internet of Things (IoT), big data in the cloud, and the increased need for patient home monitoring are a few of the factors moving the industry forward.
When designing a portable medical/healthcare device, decisions on processor and component selection are dependent on a range of variables which include performance, price, quality, and reliability. Of all these factors, reliability is perhaps the most important due to the critical nature of today’s modern digital healthcare devices.
This paper discusses the concept of usable product life as a key factor in the success of any digital health device. Product life can be extended by increasing the mean time between failures (MTBF). While there is data to measure the reliability of hardware components, often little attention is given to the role software plays in extending the usable product life of a device.
As pressure grows to condense development cycles and add software-based features, design complexity increases and the task of architecting reliability into the software design becomes even more challenging. Therefore, when starting a new project, early design considerations should include system architecture, the tool environment, as well as selecting the right operating system which can allow software developers to design in greater system reliability.
3-Stages of failure through lifecycle of connected health device
The most common models for predicting reliability of a portable health device include failure in time (FIT) and mean time between failures (MTBF). Failure models routinely focus on three stages in a component’s lifecycle: ‘Early Failure’ – due to manufacturing errors that occur following production; ‘Constant Failure’ – which occurs while the product is deployed and in service; and ‘Wear-out Failure’ – which happens at the end of a product’s intended lifespan (figure 1).
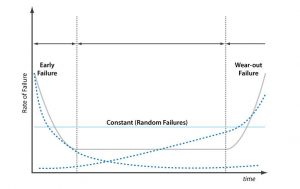
Figure 1: The potential for failure as indicated by the three stages of a component’s lifecycle.
While a detailed explanation of FIT and MTBF go beyond the scope of this paper, both models use temper ature and voltage as the key controllable variables to predict rate of failure. Basically, these are stress factors and collectively are known as acceleration factors. Controlling the failure rate while the product is in service directly correlates to controlling that product’s acceleration factors. The models suggest prolonged periods of high operating temperatures and/or increase voltage will speed up the predicted rate of failure.
The models have proven to be strong indicators of device reliability, and thus, they are very useful in predicting the failure rate. However, testing and modeling a device only indicates how much reliability is currently in the product – it does not improve product reliability itself. Any improvement in reliability must be designed into the product early in its development cycle.
Controlling power consumption & heat dissipation
Traditionally, CPUs in embedded devices operated at a single speed with essentially no options to control power consumption. When networking was introduced into embedded devices, the requirements to process data grew considerably. As a result, CPU manufacturers introduced more features into the silicon; networking engines, individual graphics and video IP blocks, DMA controllers, larger cache, and memory blocks all became common features for even low-cost processors. As CPU speeds increased along with more features, power consumption and the ability to dissipate the heat generated became a major design limitation. High-end processors addressed this by offering Dynamic Voltage and Frequency Scaling (DFVS) to support operating point transitions to low-power modes as per the requirement of the system at any given time in order reduce both power consumption and heat dissipation. In the past, the ability to change operating points based on system requirements allowed for greater control of power consumption and heat generation. Today, high-end MPUs, as well as low-cost MCUs, offer an array of power-saving features that include DFVS, idle and sleep modes, and clock and power gating (to turn off individual blocks of peripherals). And while these features lay the foundation to manage power consumption and system temperature, the burden to implement these features shifts to the application developer. Effective design can mean the difference, in some cases, between a hardware system operating effectively through passive cooling, and thus avoiding the need for active cooling through fans, which in turn, adversely affects the MTBF of a system.
Software and SoC complexity
Modern System-on-Chip (SoC) architectures are designed to interface with complex external devices for transmitting, receiving, and storing data. The power consumed by the SoC increases when external devices are driven directly. With a focus on controlling power consumption, semiconductor vendors have introduced an array of features to control the frequency, voltage, and the operational state for not only the processor, but also individual devices and the blocks of devices.
As an example, individual peripherals or blocks of peripherals can be placed in low-power modes or be shut down completely to reduce power usage and heat dissipation. Operating point transitions can be used to reduce CPU clock frequency and/or the operating voltage. When placing the processor or peripherals in low-power states, it is common for the system to require complex software to respond to the event and place the device in a low-power state so that it can be returned to the initial operational state when required.
The steps required to transition to different power states vary depending on the complexity of the device. Consider an Operating Point transition to move the system to a lower frequency to reduce heat and save power. Software is required to determine the amount of power saved compared to the amount of power used to transition in to and out of a low-power mode. Device driver software for each peripheral must be written to support the transitioning of the device to the various low-power states offered by the hardware. Software must be written to verify and log the state of each peripheral device before the transition: Is the device on or off? Is it in active or in standby? Can it be taken off line during the transition and returned without any loss of data or performance? Because devices must be taken off line in order for a transition to occur, software must be written to determine the length of time each active device can be taken off line and compared to the amount of time it will take for the transition to occur. If a device uses the system clock as a reference, for example, establishing the baud rate for a UART, then a recalculation is required after the frequency transition. Complex devices such as Wi-Fi can require software to verify the status of TCP/UDP outgoing packet buffers and IP management queues to ensure they are empty before shut down. This may require a look at the buffer descriptors for each protocol layer down to the DMA driver state. Both the amount of software and the complexity managing the power state of the system can be daunting to the software developer.
To address this, software must be designed from project inception to effectively use and manage the power-saving features embedded in the hardware in order to reduce heat dissipation. Without a software infra-structure that maps the silicon features to the software APIs, software developers must rely on their individual abilities to write both the low-level device driver software to control individual devices and the system software required to coordinate the CPU and peripheral blocks and the high-level software.
Correct operating system assures reliability
Based on failure predictability models, it can be argued that increasing system MTBF requires the proper management of power consumption (voltage management) and heat dissipation. The software complexity required for device and system management is often the barrier for the effective use of software as related to enhancing system reliability. Selecting an operating system that provides a framework to manage power consumption for both the processor and individual devices allows software developers to architect software with the intent of controlling the acceleration factors that degrade system reliability.
To illustrate this underlying framework, the Nucleus Real Time Operating System (RTOS) from Mentor Graphics will be used.
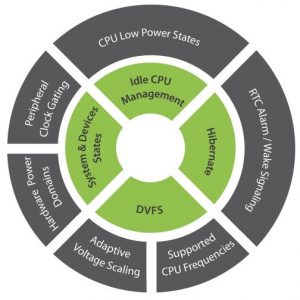
Figure 2: The Nucleus Power Management Framework takes advantage of the power-saving features available in today’s hardware.
Improving the Lifetime Operation of Today’s Digital Healthcare Devices
Nucleus provides an extensive Power Management Framework to provide efficient power management of portable medical devices. This framework enables direct mapping to the low-power features of the hardware (figure 2). The Nucleus Power Management Framework approaches the conservation of power usage and reduction of heat dissipation from four directions:
System and Device States to control peripheral power consumption.
Idle CPU Management prevents the waste of expending energy.
Hibernate and Sleep Modes allow the system to go off line to the degree that corresponds to the duration of the inactivity and restart time constraints.
Dynamic Voltage/Frequency Scaling (DFVS) focuses on the CPU core.
The Nucleus Power Management Framework also includes a device manager mechanism (figure 3) which requires a peripheral to register upon initialization, reports available power modes, and updates the device state. System and device sates are changed to manage peripheral power conservation and are tightly coupled with the core power controls through DVFS. These two components are choreographed by the device manager, which allows for a graceful power state transition of peripheral operation and CPU timing. Any alteration of one component which impacts another, results in a coordinated transition across all involved subsystems. Idle CPU management results in a temporary suspension of code execution when such execution produces no usable result. This feature is invisible to the application and results in no impact to system response time when an event requiring CPU resources occurs. Hibernate and Sleep modes provide controlled levels of sleep when an opportunity to go off line is presented. With the choice of a RAM-based or NVM-based system storage, recovery response time can be weighed against power saving, and the need to re-enter operation though a cold boot process. The code necessary to convert the high-level commands is built into the Nucleus Framework to provide software developers comprehensive control of the system.
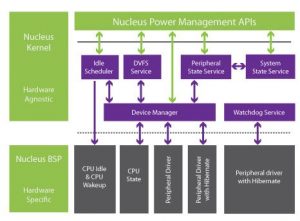
Figure 3: Nucleus power management APIs simplify use of power-saving capabilities.
Conclusion
As the trend in healthcare accelerates from hospital-centric to more of an outpatient mobile care model, today’s digital healthcare devices (including wearables for ehealth and portable medical devices such as dialysis and patient monitoring) will play a prominent role. The reliability of these devices is becoming increasingly more important as the consequences of device failure in some cases can lead to severe or dire consequences.
As this paper discussed, highly reliable devices can be designed into medical embedded systems. While many operating systems are currently available, a majority of healthcare devices require the determinism of a full-featured RTOS with strong capabilities in managing power consumption and heat dissipation – all to increase system reliability.